13. 罗马数字转整数
Tag:#字符串 #哈希
描述:
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值
I 1
V 5
X 10
L 50
C 100
D 500
M 1000例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。
示例 1:
输入: s = "III"
输出: 3示例 2:
输入: s = "IV"
输出: 4示例 3:
输入: s = "IX"
输出: 9示例 4:
输入: s = "LVIII"
输出: 58
解释: L = 50, V= 5, III = 3.示例 5:
输入: s = "MCMXCIV"
输出: 1994
解释: M = 1000, CM = 900, XC = 90, IV = 4.核心思想:
对于i字符,下一个字符j代指数字比i大,表明是 num_j - num_i,
下一个字符j代指数字比i小,或者等于i,表明是num_j + num_i
代码实现
C:
int romanToInt(char* s) {
int tables[26] ;
tables['I' - 'A'] = 1;
tables['V' - 'A'] = 5;
tables['X' - 'A'] = 10;
tables['L' - 'A'] = 50;
tables['C' - 'A'] = 100;
tables['D' - 'A'] = 500;
tables['M' - 'A'] = 1000;
int len = strlen(s);
int count = 0;
for(int i=0;i<len;++i){
int value = tables[s[i] - 'A'];
if(i<len-1 && value < tables[s[i+1] - 'A']){
count -= value;
}else {
count += value;
}
}
return count;
}Go:
func romanToInt(s string) int {
len := len(s)
res := 0
for i:=0;i<len;i++{
value := symbolValues[s[i]]
if i<len-1 && value < symbolValues[s[i+1]]{
res -= value
}else{
res += value
}
}
return res
}
var symbolValues = map[byte]int{'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}
58. 最后一个单词的长度
描述
给你一个字符串 s,由若干单词组成,单词前后用一些空格字符隔开。返回字符串中 最后一个 单词的长度。
单词 是指仅由字母组成、不包含任何空格字符的最大子字符串。
示例 1:
输入:s = "Hello World"
输出:5
解释:最后一个单词是“World”,长度为 5。示例 2:
输入:s = " fly me to the moon "
输出:4
解释:最后一个单词是“moon”,长度为 4。示例 3:
输入:s = "luffy is still joyboy"
输出:6
解释:最后一个单词是长度为 6 的“joyboy”。核心思想
从后往前遍历,遇到空格停止计数,小心最后一个也是空格情况,像示例2
代码实现
C:
int lengthOfLastWord(char* s) {
int len = strlen(s);
int count = 0;
while(s[len -1] == ' '){ //去掉尾部空格
len--;
}
if(len == 1){ //针对"a "
return 1;
}
for(int i=len-1;i>=0;i--){
if(s[i] == ' '){
return count;
}
count++;
}
return count;
}Go:
func lengthOfLastWord(s string) int {
n := len(s)
count := 0
for i:= n-1; i>= 0; i--{
if s[i] == ' '{
if count>0{
return count
}
continue
}
count++
}
return count
}14. 最长公共前缀
描述
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入:strs = ["flower","flow","flight"]
输出:"fl"示例 2:
输入:strs = ["dog","racecar","car"]
输出:""
解释:输入不存在公共前缀。核心思想
先按长度排序,找出最短字符和最长字符公共的字符前缀comPre,再把comPre和其他每个元素比较,看是否为前缀,若每个都以comPre为前缀,则返回;若有任一不是,则应该缩短前缀,继续匹配,比如["abab","aba","abc"],第一次comPre = aba,但是匹配abc时,发现是ab,应缩短为ab进行匹配
代码实现
Go:
func longestCommonPrefix(strs []string) string {
n := len(strs)
if n == 0{
return ""
}
if n == 1{
return strs[0]
}
//按长度排序
sort.Slice(strs, func(i, j int) bool {
return len(strs[i]) < len(strs[j])
})
//按最前面和最后面找出公共长度,再和其他比较
comPre := longestCommonPrefix_AB(strs[0], strs[n-1])
for i:=1;i<n-1;i++{
//strings.Index 用于查找子字符串在字符串中第一次出现的索引位置,如果未找到则返回 -1。
if strings.HasPrefix(strs[i],comPre) == false{
//发现不匹配时,缩短公共前缀
comPre = comPre[:len(comPre)-1]
i = 0 //重新开始匹配
}else{
continue
}
}
return comPre
}
// longestCommonPrefix 函数用于找出两个字符串的公共前缀
func longestCommonPrefix_AB(a, b string) string {
// 找出两个字符串中较短的长度,避免越界访问
minLen := len(a)
if len(b) < minLen {
minLen = len(b)
}
// 遍历两个字符串,逐字符比较
var i int
for i = 0; i < minLen; i++ {
if a[i] != b[i] {
break
}
}
// 返回公共前缀,可以是空“”
return a[:i]
}strings.HasPrefix 是 Go 语言标准库 strings 包中的一个函数,用于检查一个字符串是否以另一个指定的前缀字符串开头。这个函数在处理字符串时非常有用,特别是在需要验证字符串的起始部分是否符合特定条件的场景中。
函数签名
func HasPrefix(s, prefix string) bool- s :要检查的字符串。
- prefix :要检查的前缀字符串。
- 返回值:如果 s 以 prefix 开头,则返回 true ;否则返回 false 。
C:
392. 判断子序列
描述
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
进阶:
如果有大量输入的 S,称作 S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
示例 1:
输入:s = "abc", t = "ahbgdc"
输出:true示例 2:
输入:s = "axc", t = "ahbgdc"
输出:false核心思想
双指针, 相同字符i j同时移动,不一样i不动, j后移,如果j先超出范围说明没有满足的子序列,如果i先结束,说明存在子序列
代码实现
func isSubsequence(s string, t string) bool {
len_s := len(s)
len_t := len(t)
i,j := 0, 0
for i<len_s {
if j == len_t {
return false
}
if s[i] == t[j] {
i++
j++
}else{
j++
}
}
return true
}125. 验证回文串
描述
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是 回文串 ,返回 true ;否则,返回 false 。
核心思想
双指针经典题,要小心非字母的符号和空格,有字母再进行比较
代码实现
func isPalindrome(s string) bool {
// 将字符串转换为小写
s = strings.ToLower(s)
left, right := 0, len(s)-1
for left < right {
// 跳过左边的非字母数字字符
for left < right &&!unicode.IsLetter(rune(s[left])) &&!unicode.IsDigit(rune(s[left])) {
left++
}
// 跳过右边的非字母数字字符
for left < right &&!unicode.IsLetter(rune(s[right])) &&!unicode.IsDigit(rune(s[right])) {
right--
}
// 比较左右两边的字母或数字
if left < right && s[left] != s[right] {
return false
}
left++
right--
}
return true
}167. 两数之和 II - 输入有序数组
描述
给你一个下标从 1 开始的整数数组 numbers ,该数组已按 非递减顺序排列 ,请你从数组中找出满足相加之和等于目标数 target 的两个数。如果设这两个数分别是 numbers[index1] 和 numbers[index2] ,则 1 <= index1 < index2 <= numbers.length 。
以长度为 2 的整数数组 [index1, index2] 的形式返回这两个整数的下标 index1 和 index2。
你可以假设每个输入 只对应唯一的答案 ,而且你 不可以 重复使用相同的元素。
你所设计的解决方案必须只使用常量级的额外空间。
示例 1:
输入:numbers = [2,7,11,15], target = 9
输出:[1,2]
解释:2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。返回 [1, 2] 。示例 2:
输入:numbers = [2,3,4], target = 6
输出:[1,3]
解释:2 与 4 之和等于目标数 6 。因此 index1 = 1, index2 = 3 。返回 [1, 3] 。示例 3:
输入:numbers = [-1,0], target = -1
输出:[1,2]
解释:-1 与 0 之和等于目标数 -1 。因此 index1 = 1, index2 = 2 。返回 [1, 2] 。核心思想
双指针,一个在头,一个在尾,若头尾之和小于目标,则应头后移,这样能增大;若和大于目标,尾巴应前移,这样能变小,直到找到相等
代码实现
func twoSum(numbers []int, target int) []int {
var res [2] int
i,j:= 0, len(numbers)-1
for i<j {
count := numbers[i] + numbers[j]
if count == target{ break
}
if count > target{
j--
}else{
i++
}
}
res[0], res[1] = i+1,j+1
return res[:]
}20. 有效的括号
描述
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
示例 2:
输入:s = "()[]{}"
输出:true
示例 3:
输入:s = "(]"
输出:false
示例 4:
输入:s = "([])"
输出:true
核心思想
用栈,左括号直接入栈,遇到右括号弹出栈顶与之配对,配对失败说明不符合要求,false,一直配对成功,即最后栈空也没出错,返回true
代码实现
注意事项:在 for...range 循环中,char 的类型是 rune,而 stack 是 []byte 类型,m 是 map[byte]byte 类型,直接使用 char 会产生类型不匹配的错误,需要进行类型转换。
package main
func isValid(s string) bool {
n := len(s)
// 如果字符串长度小于 2 或者长度为奇数,直接返回 false
if n < 2 || n%2 == 1 {
return false
}
// 修正映射的键值对,右括号作为键,左括号作为值
m := map[byte]byte{
')': '(',
']': '[',
'}': '{',
}
stack := make([]byte, 0)
for _, char := range s {
// 将 rune 类型转换为 byte 类型
b := byte(char)
// 如果是左括号,直接入栈
if b == '(' || b == '[' || b == '{' {
stack = append(stack, b)
} else {
// 检查栈是否为空
if len(stack) == 0 {
return false
}
// 获取栈顶元素
top := stack[len(stack)-1]
// 检查栈顶元素是否与当前右括号匹配
if m[b] != top {
return false
}
// 匹配成功,栈顶元素出栈
stack = stack[:len(stack)-1]
}
}
// 最后检查栈是否为空,如果为空则所有括号匹配成功
return len(stack) == 0
}
11. 盛最多水的容器
描述
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。

输入:[1,8,6,2,5,4,8,3,7]
输出:49
解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。示例 2:
输入:height = [1,1]
输出:1核心思想
双指针,轮流移动首尾指针是错误的,移动长指针会导致变小,应移动短的指针
代码实现
func maxArea(height []int) int {
// 储水量计算公式:选定的两桶壁为i,j min{i,j}*(index_j - index_i)
i,j := 0,len(height)-1
res := 0
for i<j {
if height[i] < height[j]{
// i短
tmp := height[i] * (j-i)
if tmp>res {
res = tmp
}
i++
}else{
//j短
tmp := height[j] * (j-i)
j--
if tmp>res {
res = tmp
}
}
}
return res
}
func MinInt(a, b int) int{
if a>b {
return b
}else{
return a
}
}42. 接雨水
描述
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
输出:6
解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 示例 2:
输入:height = [4,2,0,3,2,5]
输出:9核心思想
代码实现
141. 环形链表
描述
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。示例 2:

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。核心思想
双指针追赶,兔子追乌龟,乌龟0格起步,兔子1格起步,乌龟一次走一格,兔子一次走两格
,只要有环,兔子一定追上乌龟
代码实现
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func hasCycle(head *ListNode) bool {
//快慢指针追赶,慢指针追上了,一定有环
if head == nil || head.Next == nil{
return false
}
slow := head
fast := head.Next
for slow!=fast{
if fast == nil || fast.Next== nil{
return false
}
slow = slow.Next
fast = fast.Next.Next
}ss
return true
}代码可优化,fast也从head开始,这样不用在判断fast.next是否为空
142. 环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。示例 2:
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。示例 3:
输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。核心思想
在上一题,用双指针找到环路和停留在相遇点后,设置一个p指针从头和slow一起慢步走,相遇点为入环口

代码实现
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func detectCycle(head *ListNode) *ListNode {
// 快慢指针追赶,慢指针追上了,一定有环
if head == nil {
return nil
}
slow := head
fast := head
for fast != nil && fast.Next != nil {
slow = slow.Next
fast = fast.Next.Next
if slow == fast {
// 找到环,开始找环的起始节点
p := head
for p != slow {
p = p.Next
slow = slow.Next
}
return p
}
}
// 没有环
return nil
}206. 反转链表
描述
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]示例 2:

输入:head = [1,2]
输出:[2,1]示例 3:
输入:head = []
输出:[]核心思想
原地逆置,需要三个指针

代码实现
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseList(head *ListNode) *ListNode {
var pre *ListNode
cur := head
for cur != nil {
// 1->2->3 to 1<-2 3
next := cur.Next
cur.Next = pre
pre = cur
cur = next
}
return pre
}136. 只出现一次的数字
描述
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1]
输出:1
示例 2 :
输入:nums = [4,1,2,1,2]
输出:4
示例 3 :
输入:nums = [1]
输出:1
核心思想
要求线性时间复杂度,On,不能用排序Onlgn;常量空间,那就不能用哈希。
很巧妙的方法,位运算,对于这道题,可使用异或运算 ⊕。异或运算有以下三个性质。
- 任何数和 0 做异或运算,结果仍然是原来的数,即 a⊕0=a。
- 任何数和其自身做异或运算,结果是 0,即 a⊕a=0。
- 异或运算满足交换律和结合律,即 a⊕b⊕a=b⊕a⊕a=b⊕(a⊕a)=b⊕0=b。
关键是23,有了可结合,那就把所有元素异或,两两相同抵消为0,剩下的就是单个的
代码实现
func singleNumber(nums []int) int {
res := 0 // 0 异或 a = a ,所以可初始化为0
for i:=0;i<len(nums);i++ {
res ^= nums[i]
}
return res
}137. 只出现一次的数字 II
描述
给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。
示例 1:
输入:nums = [2,2,3,2]
输出:3示例 2:
输入:nums = [0,1,0,1,0,1,99]
输出:99核心思想
束手无策呀,只能用map 时间On,空间On,一看题解什么电路设计,面试要求O1 空间那没话说,太sb了
代码实现
map方法,简单好懂,先统计所有数字出现频次
func singleNumber(nums []int) int {
m := map[int] int {}
for _,num := range nums{
m[num] ++
}
for num,co := range m {
if co == 1 {
return num
}
}
return 0 //防编译出错的
}电路设计代码,没学过啊
func singleNumber(nums []int) int {
a, b := 0, 0
for _, num := range nums {
a, b = b&^a&num|a&^b&^num, (b^num)&^a
}
return b
}
作者:力扣官方题解
链接:https://leetcode.cn/problems/single-number-ii/solutions/746993/zhi-chu-xian-yi-ci-de-shu-zi-ii-by-leetc-23t6/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。67. 二进制求和
描述
给你两个二进制字符串 a 和 b ,以二进制字符串的形式返回它们的和。
示例 1:
输入:a = "11", b = "1"
输出:"100"示例 2:
输入:a = "1010", b = "1011"
输出:"10101"核心思想
显然,是模拟二进制加法,从低位开始加,逢二进一,要考虑对位的问题,比如11和1,应该是11 和 01 加,最好用数组来承接
代码实现
1. 两数之和
描述
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]核心思想
哈希表,元素作为关键字,下标作为value值,一边遍历数组,一边排查map中有没有能配对成target的元素,这样能有效避免两次遍历for 中存在的 两个一样元素组成target的情况
代码实现
Go:
func twoSum(nums []int, target int) []int {
// 创建一个映射,用于存储每个数及其索引
hashTable := make(map[int]int)
// 遍历数组
for index, num := range nums {
// 计算当前元素的互补数
complement := target - num
// 检查互补数是否已经存在于哈希表中
if k, exists := hashTable[complement]; exists {
// 如果存在,返回这两个数的索引
return []int{k, index}
}
// 将当前元素及其索引存入哈希表
hashTable[num] = index
}
// 如果没有找到符合条件的两个数,默认返回 [0, 1]
return []int{0, 1}
}C: c的哈希表太难构造了,
27. 移除元素
描述
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素。元素的顺序可能发生改变。然后返回 nums 中与 val 不同的元素的数量。
假设 nums 中不等于 val 的元素数量为 k,要通过此题,您需要执行以下操作:
- 更改
nums数组,使nums的前k个元素包含不等于val的元素。nums的其余元素和nums的大小并不重要。 - 返回
k。
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2,_,_]
解释:你的函数函数应该返回 k = 2, 并且 nums 中的前两个元素均为 2。
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3,_,_,_]
解释:你的函数应该返回 k = 5,并且 nums 中的前五个元素为 0,0,1,3,4。
注意这五个元素可以任意顺序返回。
你在返回的 k 个元素之外留下了什么并不重要(因此它们并不计入评测)。核心思想
覆盖法:遍历,找到不是val的值,按序放到nums[0], nums[1]……中
双指针:收尾指针left,right,left遇到val停留,与right交换,但要小心交换过来的也是val值,所以left还不能移动,让right- -;只有left不是val才可以进行left++
代码实现
C:双指针
int removeElement(int* nums, int numsSize, int val) {
int right = numsSize;
int left = 0;
while(left < right){
if(nums[left] == val){
nums[left] = nums[right-1];
right--;
}else{
left++;
}
}
return left;
}C:覆盖法
int removeElement(int* nums, int numsSize, int val) {
int k = 0;
for(int i=0;i<numsSize-1;i++){
if(nums[i] != val){
nums[k++] = nums[i];
}
}
return k;
}26. 删除有序数组中的重复项
描述
给你一个 非严格递增排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。然后返回 nums 中唯一元素的个数。
考虑 nums 的唯一元素的数量为 k ,你需要做以下事情确保你的题解可以被通过:
- 更改数组
nums,使nums的前k个元素包含唯一元素,并按照它们最初在nums中出现的顺序排列。nums的其余元素与nums的大小不重要。 - 返回
k。
判题标准:
系统会用下面的代码来测试你的题解:
int[] nums = [...]; // 输入数组
int[] expectedNums = [...]; // 长度正确的期望答案
int k = removeDuplicates(nums); // 调用
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}如果所有断言都通过,那么您的题解将被 通过。
示例 1:
输入:nums = [1,1,2]
输出:2, nums = [1,2,_]
解释:函数应该返回新的长度 2 ,并且原数组 nums 的前两个元素被修改为 1, 2 。不需要考虑数组中超出新长度后面的元素。示例 2:
输入:nums = [0,0,1,1,1,2,2,3,3,4]
输出:5, nums = [0,1,2,3,4]
解释:函数应该返回新的长度 5 , 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4 。不需要考虑数组中超出新长度后面的元素。核心思想
覆盖法,遇到不一样的值再依次插入数组形成覆盖
代码实现
int removeDuplicates(int* nums, int numsSize) {
//覆盖法,和27题类似
int value = nums[0];//用来记录上一个已经出现的值
int index = 1;//用来决定插入的下标,从1一直到结果,最后返回
for (int i=1; i< numsSize;i++){ //从1开始
if (nums[i] != value){
nums[index++] = nums[i];
value = nums[i]; //更新
}
}
return index;
}80. 删除有序数组中的重复项 II
给你一个有序数组 nums ,请你 原地 删除重复出现的元素,使得出现次数超过两次的元素只出现两次 ,返回删除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}示例 1:
输入:nums = [1,1,1,2,2,3]
输出:5, nums = [1,1,2,2,3]
解释:函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3。 不需要考虑数组中超出新长度后面的元素。示例 2:
输入:nums = [0,0,1,1,1,1,2,3,3]
输出:7, nums = [0,0,1,1,2,3,3]
解释:函数应返回新长度 length = 7, 并且原数组的前七个元素被修改为 0, 0, 1, 1, 2, 3, 3。不需要考虑数组中超出新长度后面的元素。核心思想
覆盖法,增加计数器,计数器超过3才移除(覆盖)
代码实现
int removeDuplicates(int* nums, int numsSize) {
//覆盖法,和26,27题类似,进行改写,增加count计数
int value = nums[0];//用来记录上一个已经出现的值
int index = 1;//用来决定插入的下标,从1一直到结果,最后返回
int count = 1;//新增count计数,count一旦等于三,index不动,即删除多余的
for (int i=1; i< numsSize;i++){ //从1开始
if (nums[i] != value){ //不等的情况
nums[index++] = nums[i];
value = nums[i]; //更新
count = 0; //重置计数器
}else{ //等于的情况
if (count <2 ){ //0,1,可以变,value不更新
nums[index++] = nums[i];
count++;
}
// count已经是2了,不能覆盖,直到不等情况出现归0
count++;
}
}
return index;
}88. 合并两个有序数组
描述
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:最终,合并后数组不应由函数返回,而是存储在数组 nums1 中。为了应对这种情况,nums1 的初始长度为 m + n,其中前 m 个元素表示应合并的元素,后 n 个元素为 0 ,应忽略。nums2 的长度为 n 。
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。核心思想
同向倒置的双指针,因为要找出递增的,num1尾部空,方便覆盖,把两个指针都从尾部开始,选大的插入到nums1最后,要小心nums1先到底或者nums2先到底情况,直接把另一个依次插入,不用比较了
代码实现
C:
void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n) {
int i = m-1,j = n-1,k = m+n-1;
while(i>=0 || j>=0){
if(i == -1){ // num1到底了
nums1[k--] = nums2[j--];
}else if(j == -1){ //num2 到底
nums1[k--] = nums1[i--];
}else if(nums1[i] > nums2[j]){ //i大
nums1[k--] = nums1[i--];
}else{ //j大
nums1[k--] = nums2[j--];
}
}
}151. 反转字符串中的单词
描述
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue"
输出:"blue is sky the"示例 2:
输入:s = " hello world "
输出:"world hello"
解释:反转后的字符串中不能存在前导空格和尾随空格。示例 3:
输入:s = "a good example"
输出:"example good a"
解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。核心思想
把整个字符串翻转,再去除多余空格,再翻转每个单词
s = "the sky is blue"
-> s = "eulb si yks eht"
-> s = "blue is sky the"c过于原始,要自己实现翻转字符串函数,去除多余空格函数,再把每个单词翻转过来
go则有库函数
strings.Fields(s):该函数的作用是把字符串s按照一个或多个连续的空白字符(包含空格、制表符、换行符等)进行分割,最终返回一个字符串切片。借助这个函数就能去除字符串里的连续空格。strings.Join(strings.Fields(s), " "):此函数把strings.Fields(s)返回的字符串切片用单个空格连接起来,从而形成一个新的字符串,并且该字符串中只存在单个空格。
代码实现
go:
func reverseString(s string) string {
// 将字符串转换为 rune 切片
runes := []rune(s)
head := 0
tail := len(runes) - 1
for head < tail {
// 交换首尾元素
runes[head], runes[tail] = runes[tail], runes[head]
head++
tail--
}
// 将 rune 切片转换回字符串
return string(runes)
}
func reverseWords(s string) string {
s = reverseString(s)
arrString := strings.Fields(s)
for i, str := range arrString {
arrString[i] = reverseString(str) // str是副本,不会修改arrString,要用索引修改
// fmt.Println(str)
}
return strings.Join(arrString, " ")
}205. 同构字符串
描述
给定两个字符串 s 和 t ,判断它们是否是同构的。
如果 s 中的字符可以按某种映射关系替换得到 t ,那么这两个字符串是同构的。
每个出现的字符都应当映射到另一个字符,同时不改变字符的顺序。不同字符不能映射到同一个字符上,相同字符只能映射到同一个字符上,字符可以映射到自己本身。
示例 1:
输入:s = "egg", t = "add"
输出:true示例 2:
输入:s = "foo", t = "bar"
输出:false示例 3:
输入:s = "paper", t = "title"
输出:true核心思想
维护两张哈希表,对于未出现的映射,添加;对于已经出现映射,双向验证,是否和哈希表中对应,不对则返回false;全部验证成功返回true
要检查双向的映射,因为
s := "badc"
t := "baba"
// b->b s->s d->b c->a 出现了s不同字符映射到t同一字符情况,应增加t->s的映射代码实现
C:UsersAdministratorDesktopFleet_workspace205.go
Go:
func isIsomorphic(s string, t string) bool {
//map映射, s->t
sTot := map[byte]byte{}
tToS := map[byte]byte{}
for i:=0;i<len(s);i++ {
sChar := s[i]
tChar := t[i]
//s to t
if value, exists:= sTot[sChar];exists{
//存在sChar对应的tChar
if value == tChar {
continue //并且成功验证
}else{
return false
}
}else{//不存在的情况
sTot[sChar] = tChar
}
// t to s
if value, exists:= tToS[tChar];exists{
//存在sChar对应的tChar
if value == sChar {
continue //并且成功验证
}else{
return false
}
}else{//不存在的情况
tToS[tChar] = sChar
}
}
return true
}219. 存在重复元素 II
描述
给你一个整数数组 nums 和一个整数 k ,判断数组中是否存在两个 不同的索引 i 和 j ,满足 nums[i] == nums[j] 且 abs(i - j) <= k 。如果存在,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [1,2,3,1], k = 3
输出:true示例 2:
输入:nums = [1,0,1,1], k = 1
输出:true示例 3:
输入:nums = [1,2,3,1,2,3], k = 2
输出:false核心思想
哈希表,遍历数组,存入哈希表,检查哈希表中是否有相同元素,有,判断k步内;没有,继续遍历数组
代码实现
func containsNearbyDuplicate(nums []int, k int) bool {
//k步之内,是否有相等值
//存入哈希表,key:值,value:索引
hashTable := map[int] int{}
for i:=0;i<len(nums);i++ {
if value, exists := hashTable[nums[i]];exists{
if i - value <= k {
return true
}
}
hashTable[nums[i]] = i
}
return false
}455. 分发饼干
描述
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是满足尽可能多的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。
所以你应该输出 1。示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2 个孩子的胃口值分别是 1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出 2。核心思想
最恰当匹配,找到能满足孩子的最小饼干
代码实现
func findContentChildren(g []int, s []int) int {
// 最恰当匹配,对于每一个孩子,能否找到最小满足的饼干
sort.Ints(s)
sort.Ints(g)
count := 0
for _,num := range g{
index := leastSatisfy(num, s)
if index != -1 {
s[index] = 0
count++
}
}
return count
}
func leastSatisfy(g int, s []int) int {
//返回满足的下标,找不到返回-1
for index, num := range s {
if num >= g {
return index
}
}
return -1
}其实排序后有更简单的贪心
func findContentChildren(g []int, s []int) int {
// 对孩子的胃口值和饼干尺寸进行排序
sort.Ints(g)
sort.Ints(s)
child := 0
cookie := 0
for child < len(g) && cookie < len(s) {
if s[cookie] >= g[child] {
// 找到合适的饼干,满足一个孩子
child++
}
// 无论是否满足孩子,都要移动到下一块饼干
cookie++
}
return child
}
942. 增减字符串匹配
描述
由范围 [0,n] 内所有整数组成的 n + 1 个整数的排列序列可以表示为长度为 n 的字符串 s ,其中:
- 如果
perm[i] < perm[i + 1],那么s[i] == 'I' - 如果
perm[i] > perm[i + 1],那么s[i] == 'D'
给定一个字符串 s ,重构排列 perm 并返回它。如果有多个有效排列perm,则返回其中 任何一个 。
核心思想
贪心,遇I找 待填序列中最小值,遇D找代填中最大值
代码实现
func diStringMatch(s string) []int {
// 第一反应 构造排序树,不太行,树形观察法可以,代码呈现很难
// 分析, IDID, 增减增减, 为了有的增,在增前,应该选择 最小的
// 满足I的最小值
//满足D的最大值
n := len(s)
res := make([]int, n+1)
//最大,最小用双指针来实现
low := 0
high := n
for i,char := range s {
if char == 'I' {
res[i] = low
low++
}else {
res[i] = high
high--
}
}
res[n] = low
return res
}509. 斐波那契数
描述
斐波那契数 (通常用 F(n) 表示)形成的序列称为 斐波那契数列 。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0,F(1) = 1
F(n) = F(n - 1) + F(n - 2),其中 n > 1给定 n ,请计算 F(n) 。
示例 1:
输入:n = 2
输出:1
解释:F(2) = F(1) + F(0) = 1 + 0 = 1核心思想
典中典,递归应用的模范题,但是递归时间耗费高,也能过
DP
代码实现
func fib(n int) int {
if n == 0 {
return 0
}
if n == 1 {
return 1
}
return fib(n-1) + fib(n-2)
}时间O2^n 空间On
DP:
func fib(n int) int {
// dp[n] = dp[n-1] + dp[n-2]
if n<2 {
return n
}
res := 0
n1 := 0
n2 := 1
for i:=1;i<n;i++{
res = n1 + n2
n1,n2 = n2,res
}
return res
}复杂度On,空间O1
28. 找出字符串中第一个匹配项的下标
描述
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。
示例 1:
输入:haystack = "sadbutsad", needle = "sad"
输出:0
解释:"sad" 在下标 0 和 6 处匹配。
第一个匹配项的下标是 0 ,所以返回 0 。示例 2:
输入:haystack = "leetcode", needle = "leeto"
输出:-1
解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。核心思想
字符串匹配,KMP算法,计算nextval,
计算 nextval 数组的步骤
- 初始化:让
nextval[0]等于 -1。 - 逐个计算:从模式串的第二个字符开始,依据next数组的值来计算nextval数组的值。
- 若
pattern[i]与pattern[next[i]]相等,那么nextval[i]就等于nextval[next[i]]。 - 若
pattern[i]与pattern[next[i]]不相等,那么nextval[i]就等于next[i]。
- 若
代码实现
290. 单词规律
描述
给定一种规律 pattern 和一个字符串 s ,判断 s 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 s 中的每个非空单词之间存在着双向连接的对应规律。
核心思想
哈希表建立双向映射,和205同理
代码实现
Go: On On
func wordPattern(pattern string, s string) bool {
// 双向联系,要两个哈希表
pToS := make(map[rune]string) // str -> word :rune->strig
sToP := make(map[string]rune)
sArr := strings.Fields(s) //返回字符串切片
if len(pattern) != len(sArr) {
return false
}
for i,str := range pattern { // str是切片
word := sArr[i] // word是字符串
if value,exists := pToS[str];exists { // 存在
if value != word {
return false
}
}else if value,exists := sToP[word];exists {
if str != value {
return false
}
}
//
pToS[str] = word
sToP[word] = str
}
return true
}2610. 转换二维数组
描述
给你一个整数数组 nums 。请你创建一个满足以下条件的二维数组:
- 二维数组应该 只 包含数组
nums中的元素。 - 二维数组中的每一行都包含 不同 的整数。
- 二维数组的行数应尽可能 少 。
返回结果数组。如果存在多种答案,则返回其中任何一种。
请注意,二维数组的每一行上可以存在不同数量的元素。
示例 1:
输入:nums = [1,3,4,1,2,3,1]
输出:[[1,3,4,2],[1,3],[1]]
解释:根据题目要求可以创建包含以下几行元素的二维数组:
- 1,3,4,2
- 1,3
- 1
nums 中的所有元素都有用到,并且每一行都由不同的整数组成,所以这是一个符合题目要求的答案。
可以证明无法创建少于三行且符合题目要求的二维数组。示例 2:
输入:nums = [1,2,3,4]
输出:[[4,3,2,1]]
解释:nums 中的所有元素都不同,所以我们可以将其全部保存在二维数组中的第一行。核心思想
https://leetcode.cn/problems/convert-an-array-into-a-2d-array-with-conditions/solutions/2204116/ha-xi-biao-mo-ni-by-endlesscheng-6rgb

代码实现
func findMatrix(nums []int) [][]int {
//遇到重复的要新开一行
m := make(map[int]int)
for _,num := range nums {
m[num]++
}
ans := [][]int{}
for len(m) > 0 {
row := make([]int, 0, len(m))
for x := range m {
row = append(row, x)
m[x]--
if m[x] == 0 {
delete(m, x)
}
}
ans = append(ans, row)
}
return ans
}189. 轮转数组
描述
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
输入: nums = [1,2,3,4,5,6,7], k = 3
输出: [5,6,7,1,2,3,4]
解释:
向右轮转 1 步: [7,1,2,3,4,5,6]
向右轮转 2 步: [6,7,1,2,3,4,5]
向右轮转 3 步: [5,6,7,1,2,3,4]示例 2:
输入:nums = [-1,-100,3,99], k = 2
输出:[3,99,-1,-100]
解释:
向右轮转 1 步: [99,-1,-100,3]
向右轮转 2 步: [3,99,-1,-100]核心思想
k = 3,分别翻转0-2 ,2-end
| 操作 | 结果 |
|---|---|
| 原始数组 | 1 2 3 4 5 6 7 |
| 翻转所有元素 | 7 6 5 4 3 2 1 |
| 翻转 [0,kmodn−1] 区间的元素 | 5 6 7 4 3 2 1 |
| 翻转 [kmodn,n−1] 区间的元素 | 5 6 7 1 2 3 4 |
代码
void reverse(int* nums, int left, int right){
int l = left, r = right;
int tmp = 0;
while(l<r){
tmp = nums[l];
nums[l] = nums[r];
nums[r] = tmp;
l++;
r--;
}
}
void rotate(int* nums, int numsSize, int k) {
// 和151反转字符一个思想
k = k % numsSize;
// 先反转所有元素
reverse(nums, 0, numsSize-1);
// 以k个分为前后段,分别反转前后段
reverse(nums, 0, k-1);
reverse(nums, k, numsSize-1);
}368. 最大整除子集
描述
给你一个由 无重复 正整数组成的集合 nums ,请你找出并返回其中最大的整除子集 answer ,子集中每一元素对 (answer[i], answer[j]) 都应当满足:
answer[i] % answer[j] == 0,或answer[j] % answer[i] == 0
如果存在多个有效解子集,返回其中任何一个均可。
示例 1:
输入:nums = [1,2,3]
输出:[1,2]
解释:[1,3] 也会被视为正确答案。示例 2:
输入:nums = [1,2,4,8]
输出:[1,2,4,8]核心思想
代码
71. 简化路径
描述
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 '/' 开头),请你将其转化为 更加简洁的规范路径。
在 Unix 风格的文件系统中规则如下:
- 一个点
'.'表示当前目录本身。 - 此外,两个点
'..'表示将目录切换到上一级(指向父目录)。 - 任意多个连续的斜杠(即,
'//'或'///')都被视为单个斜杠'/'。 - 任何其他格式的点(例如,
'...'或'....')均被视为有效的文件/目录名称。
返回的 简化路径 必须遵循下述格式:
- 始终以斜杠
'/'开头。 - 两个目录名之间必须只有一个斜杠
'/'。 - 最后一个目录名(如果存在)不能 以
'/'结尾。 - 此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含
'.'或'..')。
返回简化后得到的 规范路径 。
**示例 1:**
**输入:**path = "/home/"
**输出:**"/home"
**解释:**
应删除尾随斜杠。
**示例 2:**
**输入:**path = "/home//foo/"
**输出:**"/home/foo"
**解释:**
多个连续的斜杠被单个斜杠替换。
**示例 3:**
**输入:**path = "/home/user/Documents/../Pictures"
**输出:**"/home/user/Pictures"
**解释:**
两个点 ".." 表示上一级目录(父目录)。
**示例 4:**
**输入:**path = "/../"
**输出:**"/"
**解释:**
不可能从根目录上升一级目录。
**示例 5:**
**输入:**path = "/.../a/../b/c/../d/./"
**输出:**"/.../b/d"
**解释:**
"..." 在这个问题中是一个合法的目录名。核心思想
遇到..要回退上一个目录,想到栈,碰到..让栈顶出栈
代码
func simplifyPath(path string) string {
if path == "/../"{ //示例4,错误路径
return "/"
}
//栈
var stack []string
//以 / 划分字符串
arrPath := strings.Split(path, "/")
for _,name := range arrPath{
if name == ".." {
// pop
if len(stack) > 0 { //不判断回爆栈
stack = stack[:len(stack) - 1]
}
}else if name != "" && name != "." {
stack = append(stack, name)
}
}
// 目录在stack里面, stack[0] 是底部,从头遍历即可
return "/" + strings.Join(stack, "/")
}155. 最小栈
描述
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
MinStack()初始化堆栈对象。void push(int val)将元素val推入堆栈。void pop()删除堆栈顶部的元素。int top()获取堆栈顶部的元素。int getMin()获取堆栈中的最小元素。
示例 1:
输入:
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
输出:
[null,null,null,null,-3,null,0,-2]
解释:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.核心思想
要求时间O1,可以借用辅助栈来存当前最小,辅助栈和 数据栈同步的出栈入栈,空间是On
如果要求空间也O1,核心思路是在栈中只保存一个栈顶元素与当前最小值的差值,而非直接保存元素本身,这样可以在常数空间内实现最小栈的功能。
代码
空间On
type MinStack struct {
stack []int
minStack []int
}
func Constructor() MinStack {
//构造函数
return MinStack{
stack: []int {},
minStack: []int {math.MaxInt64},
}
}
func (this *MinStack) Push(val int) {
// Push 任务:1.压入数据栈stack 2.找到当前最小元素压入最小栈
this.stack = append(this.stack, val)
//当前val和最小栈的栈顶比较,看哪个小,插入小的到minS
minVal := this.minStack[len(this.minStack)-1]
this.minStack = append(this.minStack, min(minVal, val))
}
func (this *MinStack) Pop() {
// Pop任务:1.数据栈出栈一个 2.最小栈出栈一个
this.stack = this.stack[:len(this.stack)-1]
this.minStack = this.minStack[:len(this.minStack)-1]
}
func (this *MinStack) Top() int {
return this.stack[len(this.stack)-1]
}
func (this *MinStack) GetMin() int {
return this.minStack[len(this.minStack)-1]
}
func min(a int, b int) int{
if a > b {
return b
}
return a
}
/**
* Your MinStack object will be instantiated and called as such:
* obj := Constructor();
* obj.Push(val);
* obj.Pop();
* param_3 := obj.Top();
* param_4 := obj.GetMin();
*/空间O1:
package main
import (
"math"
)
type MinStack struct {
stack []int
minVal int
}
func Constructor() MinStack {
return MinStack{
stack: []int{},
minVal: math.MaxInt64,
}
}
func (this *MinStack) Push(val int) {
if len(this.stack) == 0 {
this.stack = append(this.stack, 0)
this.minVal = val
} else {
diff := val - this.minVal
this.stack = append(this.stack, diff)
if diff < 0 {
this.minVal = val
}
}
}
func (this *MinStack) Pop() {
if len(this.stack) > 0 {
diff := this.stack[len(this.stack)-1]
this.stack = this.stack[:len(this.stack)-1]
if diff < 0 {
this.minVal = this.minVal - diff
}
}
}
func (this *MinStack) Top() int {
if len(this.stack) > 0 {
diff := this.stack[len(this.stack)-1]
if diff < 0 {
return this.minVal
}
return this.minVal + diff
}
return 0
}
func (this *MinStack) GetMin() int {
return this.minVal
}
- 结构体定义:
MinStack结构体包含一个切片stack用于存储元素与最小值的差值,以及一个整数minVal用于记录当前栈中的最小值。 - 构造函数
Constructor:初始化stack为空切片,minVal为math.MaxInt64,表示初始时最小元素为极大值。 Push方法:- 当栈为空时,将差值
0压入栈,并将当前元素val设为最小值。 - 当栈不为空时,计算当前元素
val与当前最小值minVal的差值diff并压入栈。若diff小于0,则更新minVal为val。
- 当栈为空时,将差值
Pop方法:- 若栈不为空,弹出栈顶的差值
diff。 - 若
diff小于0,说明弹出的元素是之前的最小值,更新minVal为minVal - diff。
- 若栈不为空,弹出栈顶的差值
Top方法:- 若栈不为空,获取栈顶的差值
diff。 - 若
diff小于0,则栈顶元素就是当前最小值,直接返回minVal;否则,返回minVal + diff。
- 若栈不为空,获取栈顶的差值
GetMin方法:直接返回minVal,即当前栈中的最小值。
复杂度分析
- 时间复杂度:
Push、Pop、Top和GetMin操作的时间复杂度均为 (O(1))。 - 空间复杂度:只使用了常数级的额外空间,空间复杂度为 (O(1))。
150. 逆波兰表达式求值
描述
给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。
请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。 - 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
示例 1:
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9示例 2:
输入:tokens = ["4","13","5","/","+"]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"]
输出:22
解释:该算式转化为常见的中缀算术表达式为:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22核心思想
使用一个栈存储操作数,从左到右遍历逆波兰表达式,进行如下操作:
如果遇到操作数,则将操作数入栈;
如果遇到运算符,则将两个操作数出栈,其中先出栈的是右操作数,后出栈的是左操作数,使用运算符对两个操作数进行运算,将运算得到的新操作数入栈。
整个逆波兰表达式遍历完毕之后,栈内只有一个元素,该元素即为逆波兰表达式的值。
代码
func evalRPN(tokens []string) int {
// 栈
var stack []int
for _,token := range tokens {
num, err := strconv.Atoi(token)
if err == nil {
//是数字,压栈
stack = append(stack, num)
}else{
// 不是数字,符号,让两个出栈运算
num1 := stack[len(stack)-1]
num2 := stack[len(stack)-2]
stack = stack[:len(stack)-1]
stack = stack[:len(stack)-1]
res,_ :=calculateWithMap(num2, num1, token) //注意次序,
// 把结果压栈
stack = append(stack, res)
}
}
return stack[0]
}
// 方法二:使用 map 映射
func calculateWithMap(num1, num2 int, operator string) (int, error) {
operators := map[string]func(int, int) int{
"+": func(a, b int) int { return a + b },
"-": func(a, b int) int { return a - b },
"*": func(a, b int) int { return a * b },
"/": func(a, b int) int {
if b == 0 {
panic("除数不能为零")
}
return a / b
},
}
op, exists := operators[operator]
if!exists {
return 0, fmt.Errorf("不支持的运算符: %s", operator)
}
return op(num1, num2), nil
}2. 两数相加
描述
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
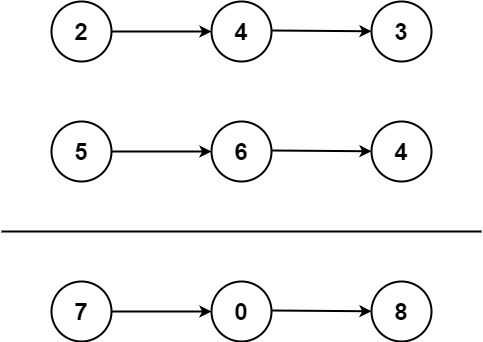
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.示例 2:
输入:l1 = [0], l2 = [0]
输出:[0]示例 3:
输入:l1 = [9,9,9,9,9,9,9], l2 = [9,9,9,9]
输出:[8,9,9,9,0,0,0,1]核心思想
模拟从低位到高位,进位,创建一个新链表接收 和
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func newListNode(val int) *ListNode {
return &ListNode{Val: val, Next: nil}
}
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
dummyHead := newListNode(0) //头指针,没用的,返回结果
current := dummyHead
carry := 0
for l1 != nil || l2 != nil || carry != 0 {
//当两个链表到尾部,进位为0才结束
sum := carry
if l1 != nil {
sum += l1.Val
l1 = l1.Next
}
if l2 != nil {
sum += l2.Val
l2 = l2.Next
}
carry = sum / 10
current.Next = newListNode(sum % 10)
current = current.Next
}
return dummyHead.Next
}
3396. 使数组元素互不相同所需的最少操作次数
描述
给你一个整数数组 nums,你需要确保数组中的元素 互不相同 。为此,你可以执行以下操作任意次:
- 从数组的开头移除 3 个元素。如果数组中元素少于 3 个,则移除所有剩余元素。
注意:空数组也视作为数组元素互不相同。返回使数组元素互不相同所需的 最少操作次数 。
**示例 1:**
**输入:** nums = [1,2,3,4,2,3,3,5,7]
**输出:** 2
**解释:**
- 第一次操作:移除前 3 个元素,数组变为 [4, 2, 3, 3, 5, 7]。
- 第二次操作:再次移除前 3 个元素,数组变为 [3, 5, 7],此时数组中的元素互不相同。
因此,答案是 2。
**示例 2:**
**输入:** nums = [4,5,6,4,4]
**输出:** 2
**解释:**
- 第一次操作:移除前 3 个元素,数组变为 [4, 4]。
- 第二次操作:移除所有剩余元素,数组变为空。
因此,答案是 2。
**示例 3:**
**输入:** nums = [6,7,8,9]
**输出:** 0
**解释:**
数组中的元素已经互不相同,因此不需要进行任何操作,答案是 0。核心思想
本质是要找到数组 后面一段无重复元素的位置 开始点
模拟法:
模拟每次移除的操作,然后用map判断是否有重复元素
从后遍历法:
从后遍历,找到第一个会使数组元素重复的位置,前面的都要移出
代码
模拟法:
func minimumOperations(nums []int) int {
// 1.移除前三个的函数
// 2.判断是否互不相同函数
// 其实不用真的移除,返回的只是次数
n := len(nums)
res := 0
for i:=0; i<n; i += 3 {
if isDiff(i, nums) {
return res
}
res++
}
return res
}
func isDiff(left int, nums []int) bool {
m := make(map[int]bool)
for left < len(nums) {
if m[nums[left]] {
return false // 有重复
}else{
m[nums[left]] = true
left++
}
}
return true // 无重复
}从后遍历法:
func minimumOperations(nums []int) int {
n := len(nums)
m := make(map[int]bool)
res := 0
for i:=n-1; i>=0 ; i--{
if m[nums[i]] {
return i/3+1
}else{
m[nums[i]] = true
}
}
return res
}
121. 买卖股票的最佳时机
描述
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
输入:[7,1,5,3,6,4]
输出:5
解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。示例 2:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 没有交易完成, 所以最大利润为 0。核心思想
要找到最低位点,也就是minPrices,但是最大利润又不一定是最小值买入,在最小值之后卖出,因为

所以还要维护最大利润maxProfit,有更大的就更新。
动态维护当前最低位和最大利润
代码
func maxProfit(prices []int) int {
if len(prices) == 0 {
return 0
}
minPrice := prices[0]
maxProfit := 0
for _, price := range prices {
if price < minPrice {
minPrice = price
} else if price - minPrice > maxProfit {
maxProfit = price - minPrice
}
}
return maxProfit
}122. 买卖股票的最佳时机 II
描述
给你一个整数数组 prices ,其中 prices[i] 表示某支股票第 i 天的价格。
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
示例 1:
输入:prices = [7,1,5,3,6,4]
输出:7
解释:在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4。
随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6 - 3 = 3。
最大总利润为 4 + 3 = 7 。示例 2:
输入:prices = [1,2,3,4,5]
输出:4
解释:在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5 - 1 = 4。
最大总利润为 4 。示例 3:
输入:prices = [7,6,4,3,1]
输出:0
解释:在这种情况下, 交易无法获得正利润,所以不参与交易可以获得最大利润,最大利润为 0。核心思想
看成两天都交易,形成n-1个交易利润总和,如果亏了就不卖,只要前后两天有得赚我就卖掉
代码
func maxProfit(prices []int) int {
// 前后两天,有差值我就卖
res := 0
for i:=1; i<len(prices); i++ {
count := prices[i] - prices[i-1]
if count > 0 {
res += count
}
}
return res
}128. 最长连续序列
描述
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9示例 3:
输入:nums = [1,0,1,2]
输出:3核心思想
关键要求On时间,所以不能排序,排序是nlogn,O1查找想到哈希,把数组放到hash中,然后遍历哈希表,并且找到每个连续序列起点,遍历,记下长度,继续遍历整个hash,得到最长长度。
代码
func longestConsecutive(nums []int) int {
m := make(map[int]bool)
for _, x := range nums {
m[x] = true
}
ans := 0
for n := range m {
if m[n-1] == true {
continue // 找到头开始,能避免很多不必要的查找
}
y := n+1
for m[y] {
y++
}
ans = max(ans, y-n)
}
return ans
}228. 汇总区间
描述
给定一个 无重复元素 的 有序 整数数组 nums 。
返回 恰好覆盖数组中所有数字 的 最小有序 区间范围列表 。也就是说,nums 的每个元素都恰好被某个区间范围所覆盖,并且不存在属于某个范围但不属于 nums 的数字 x 。
列表中的每个区间范围 [a,b] 应该按如下格式输出:
"a->b",如果a != b"a",如果a == b
示例 1:
输入:nums = [0,1,2,4,5,7]
输出:["0->2","4->5","7"]
解释:区间范围是:
[0,2] --> "0->2"
[4,5] --> "4->5"
[7,7] --> "7"示例 2:
输入:nums = [0,2,3,4,6,8,9]
输出:["0","2->4","6","8->9"]
解释:区间范围是:
[0,0] --> "0"
[2,4] --> "2->4"
[6,6] --> "6"
[8,9] --> "8->9"提示:
0 <= nums.length <= 20-231 <= nums[i] <= 231 - 1nums中的所有值都 互不相同nums按升序排列
核心思想
第一反应想到最长序列,找到每个连续序列不就有了区间吗,同样是hash
移植128的代码,但发现不对,go中的map是乱序遍历,参考mistakes of golang
改用双指针,low在起点不动,high往后走,直到最长序列,添加到结果;low转向high+1,high继续向后走
代码
104. 二叉树的最大深度
描述
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:

输入:root = [3,9,20,null,null,15,7]
输出:3示例 2:
输入:root = [1,null,2]
输出:2核心思想
DFS深搜的思想
代码
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func maxDepth(root *TreeNode) int {
if root == nil {
return 0
}
return max(maxDepth(root.Left), maxDepth(root.Right))+1
}15. 三数之和
描述
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
输入:nums = [-1,0,1,2,-1,-4]
输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。示例 2:
输入:nums = [0,1,1]
输出:[]
解释:唯一可能的三元组和不为 0 。核心思想
排序,然后固定一个数,转为双指针的问题,二数之和
注意点:1.不能有重复的,那遇到同样的数要跳过,i,j,k都要跳
2.数组的添加数组,ans = append(ans, []int{nums[i], nums[j], nums[k]})
代码
func threeSum(nums []int) [][]int {
var ans [][]int
n := len(nums)
sort.Ints(nums)
// i j k
i := 0
for i < n-2 {
if i>0 && nums[i] == nums[i-1] { // 跳过重复的i
i++
continue //不可少!不执行下面代码跳到下一个循环
}
j := i+1
k := n-1
for j < k {
sum := nums[i] + nums[j] + nums[k]
if sum == 0 {
ans = append(ans, []int{nums[i], nums[j], nums[k]})
for j<k && nums[k] == nums[k-1] {
k--
}
for j<k && nums[j+1] == nums[j] {
j++
}
k--
j++
}else if sum > 0 {
k--
}else if sum < 0 {
j++
}
}
i++
}
return ans
}2843. 统计对称整数的数目
描述
给你两个正整数 low 和 high 。
对于一个由 2 * n 位数字组成的整数 x ,如果其前 n 位数字之和与后 n 位数字之和相等,则认为这个数字是一个对称整数。
返回在 [low, high] 范围内的 对称整数的数目 。
示例 1:
输入:low = 1, high = 100
输出:9
解释:在 1 到 100 范围内共有 9 个对称整数:11、22、33、44、55、66、77、88 和 99 。示例 2:
输入:low = 1200, high = 1230
输出:4
解释:在 1200 到 1230 范围内共有 4 个对称整数:1203、1212、1221 和 1230 。核心思想
获取前n位和,主要还是数字转字符串,然后byte转数字求和
代码
func countSymmetricIntegers(low int, high int) int {
ans := 0
//奇数位数肯定不是
for x:=low; x<= high; x++ {
digitN := digit(x)
if digitN % 2 != 0 {
continue
}else{
leftSum := sumOrderDigits(x, 0, digitN/2-1)
rightSum := sumOrderDigits(x, digitN/2, digitN-1)
if leftSum == rightSum {
ans++
}
}
}
return ans
}
func digit(n int) int {
// 输入数字,返回数字位数
strN := strconv.Itoa(n)
return len(strN)
}
func sumOrderDigits(n, l, r int) int {
//计算指定位数之间和 [l,r]
sum := 0
strN := strconv.Itoa(n)
for i:=l; i<=r; i++ {
sum += int(strN[i] - '0')
}
return sum
}380. O(1) 时间插入、删除和获取随机元素
描述
实现RandomizedSet 类:
RandomizedSet()初始化RandomizedSet对象bool insert(int val)当元素val不存在时,向集合中插入该项,并返回true;否则,返回false。bool remove(int val)当元素val存在时,从集合中移除该项,并返回true;否则,返回false。int getRandom()随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。
你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
示例:
输入
["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"]
[[], [1], [2], [2], [], [1], [2], []]
输出
[null, true, false, true, 2, true, false, 2]
解释
RandomizedSet randomizedSet = new RandomizedSet();
randomizedSet.insert(1); // 向集合中插入 1 。返回 true 表示 1 被成功地插入。
randomizedSet.remove(2); // 返回 false ,表示集合中不存在 2 。
randomizedSet.insert(2); // 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。
randomizedSet.getRandom(); // getRandom 应随机返回 1 或 2 。
randomizedSet.remove(1); // 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。
randomizedSet.insert(2); // 2 已在集合中,所以返回 false 。
randomizedSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。核心思想
用哈希可以实现O1查找,增删,但是随机返回则需要用数组辅助
代码
type RandomizedSet struct {
// key: 值 value: 数组中的下标
m map[int]int
// 数组就是为随机函数服务的
arr []int
}
func Constructor() RandomizedSet {
return RandomizedSet{
m: make(map[int]int),
arr: make([]int, 0),
}
}
func (this *RandomizedSet) Insert(val int) bool {
if _, exists := this.m[val];exists {
return false
}else{
this.arr = append(this.arr, val)
this.m[val] = len(this.arr) - 1
return true
}
}
func (this *RandomizedSet) Remove(val int) bool {
//先判断是否在map里
//从数组删去一个元素是麻烦的,因为要找到元素,缩小数组容量
// 一个巧妙做法,让目标index和尾部交换,删掉尾部
// 但是,相当于把尾部元素a,放到了index的位置,所以要更新map中a的value值,更新成index
//要注意次序,先更新map,在更改arr,否则尾部元素不好找
n := len(this.arr)
if index, exists := this.m[val];exists {
//更新map
this.m[this.arr[n-1]] = index
// swap
this.arr[index], this.arr[n-1] = this.arr[n-1], this.arr[index]
this.arr = this.arr[:n-1]
// index 是value值,也是数组中索引
delete(this.m, val)
return true
}else {
return false
}
}
func (this *RandomizedSet) GetRandom() int {
n := len(this.arr)
return this.arr[rand.Intn(n)]
}
/**
* Your RandomizedSet object will be instantiated and called as such:
* obj := Constructor();
* param_1 := obj.Insert(val);
* param_2 := obj.Remove(val);
* param_3 := obj.GetRandom();
*/55. 跳跃游戏
描述
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。核心思想
贪心,覆盖范围能到n-1,则返回true
代码
错误示范:这样默认都能到达n-2的位置,其实是不一定的,要看覆盖范围决定最远到多少,for循环的边界应该是上一个范围cover
func canJump(nums []int) bool {
n := len(nums)
if n == 1{
return true
}
for i:=0; i<n-1; i++ {
if i + nums[i] >= n-1 {
return true
}
}
return false
}正确答案:
func canJump(nums []int) bool {
n := len(nums)
cover := 0
if n == 1{
return true
}
for i:=0; i<=cover; i++ { //cover边界
cover = max(cover, i+nums[i]) //更新能到达最远范围
if cover >= n-1 {
return true
}
}
return false
}160. 相交链表
描述
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:

题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。核心思想
来源https://leetcode.cn/problems/intersection-of-two-linked-lists/solutions/2958778/tu-jie-yi-zhang-tu-miao-dong-xiang-jiao-m6tg1

代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func getIntersectionNode(headA, headB *ListNode) *ListNode {
p, q := headA, headB
for p != q {
if p != nil {
p = p.Next
}else { // 走到终点了,没找到q,走q走过的路
p = headB
}
if q != nil {
q = q.Next
}else{
q = headA
}
}
return p
}303. 区域和检索 - 数组不可变
描述
给定一个整数数组 nums,处理以下类型的多个查询:
- 计算索引
left和right(包含left和right)之间的nums元素的 和 ,其中left <= right
实现 NumArray 类:
NumArray(int[] nums)使用数组nums初始化对象int sumRange(int i, int j)返回数组nums中索引left和right之间的元素的 总和 ,包含left和right两点(也就是nums[left] + nums[left + 1] + ... + nums[right])
示例 1:
输入:
["NumArray", "sumRange", "sumRange", "sumRange"]
[[[-2, 0, 3, -5, 2, -1]], [0, 2], [2, 5], [0, 5]]
输出:
[null, 1, -1, -3]
解释:
NumArray numArray = new NumArray([-2, 0, 3, -5, 2, -1]);
numArray.sumRange(0, 2); // return 1 ((-2) + 0 + 3)
numArray.sumRange(2, 5); // return -1 (3 + (-5) + 2 + (-1))
numArray.sumRange(0, 5); // return -3 ((-2) + 0 + 3 + (-5) + 2 + (-1))核心思想
前缀和,

$s[i+1] == s[i] + a[i]$,所以$a[left]+...+a[right] = s[right-1] - s[left]$
因为会进行无限次的区间和检索,在构建类时就应该返回前缀和数组,这样查找的复杂度就是O1,不会超时。
s[0]=0,是为了边界服务的,left=0,right=n-1时,直接就是s[n] - 0
代码
type NumArray struct {
// NumArr存在目的就是找区间和,不会有找单个元素需求
arr []int
}
func Constructor(nums []int) NumArray {
s := make([]int, len(nums)+1) // 加1为了给s[0]=0,方便找0-n区间和
for i,x := range nums {
s[i+1] = s[i] + x // s[0] 默认0,没有进行赋值
}
return NumArray{
arr: s,
}
}
func (this *NumArray) SumRange(left int, right int) int {
return this.arr[right+1] - this.arr[left]
}
/**
* Your NumArray object will be instantiated and called as such:
* obj := Constructor(nums);
* param_1 := obj.SumRange(left,right);
*/560. 和为 K 的子数组
描述
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
输入:nums = [1,1,1], k = 2
输出:2示例 2:
输入:nums = [1,2,3], k = 3
输出:2核心思想
前缀和+两数之和map
代码
func subarraySum(nums []int, k int) int {
// 排序是错误思路,会改变连续子序列
// 看成 前缀和 + 两数之和
// 在前缀和数组,找到 s[j] - s[i] == k 的个数,就是子数组个数
s := make([]int, len(nums)+1)
s[0] = 0
for i:=0; i<len(nums); i++ {
s[i+1] = nums[i] + s[i]
// fmt.Println(s[i+1])
}
// 两数之和做法。用map, key:s数组元素 val: count,因为有相同的数,要进行计数
m := make(map[int]int)
ans := 0
// s[j] - s[i] == k, for j : find s[i] == s[j] - k
// find exists in map [x - k ] == 1 , ans++
for _,x := range s {
target := x - k
if count, exists := m[target]; exists {
ans += count
}
m[x]++
}
return ans
}234. 回文链表
描述
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1]
输出:true示例 2:

输入:head = [1,2]
输出:false核心思想
On空间复杂度,直接遍历链表生成对应数组,数组头尾指针遍历
O1空间复杂度,找到中心点,从中心点反转链表,这样的到两个链表,head和tail,同时遍历
代码
转为数组:
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func isPalindrome(head *ListNode) bool {
// 不要求空间O1就直接遍历到数组中,当回文串处理
arr := make([]int, 0)
n := 0
for head != nil {
n++
arr = append(arr, head.Val)
head = head.Next
}
i := 0
j := n-1
for i < j {
if arr[i] == arr[j] {
i++
j--
continue
}else{
return false
}
}
return true
}快慢指针找中心点,反转链表,双指针变遍历
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func isPalindrome(head *ListNode) bool {
// 空间O1做法 找到中心点,206从尾部反转链表,进行双指针遍历
if head == nil || head.Next == nil {
return true
}
slow := head
fast := head
for fast.Next != nil && fast.Next.Next != nil{
slow = slow.Next
fast = fast.Next.Next
}
// slow 停在中心点
tail := reverseList(slow)
for head != nil && tail != nil {
if head.Val == tail.Val {
head = head.Next
tail = tail.Next
continue
}else{
return false
}
}
return true
}
// 206题解
func reverseList(head *ListNode) *ListNode {
var pre *ListNode
cur := head
for cur != nil {
next := cur.Next
cur.Next = pre
pre = cur
cur = next
}
return pre
}19. 删除链表的倒数第 N 个结点
描述
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]示例 2:
输入:head = [1], n = 1
输出:[]示例 3:
输入:head = [1,2], n = 1
输出:[1]核心思想
快慢指针,间隔n个结点,遍历一趟,找到要删去结点的前一个。
这种没有空头指针的链表加上一个哨兵结点,也就是空头结点能方便很多,因为有删掉原head的情况
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeNthFromEnd(head *ListNode, n int) *ListNode {
if head == nil || head.Next == nil {
return nil
}
// 加哨兵结点,也就是空结点当头
dummy := &ListNode{Next: head}
slow := dummy
fast := dummy
for n>0 {
fast = fast.Next
n--
}
for fast.Next != nil {
slow = slow.Next
fast = fast.Next
}
// slow指向要删的前一个
// fmt.Println(slow.Val)
slow.Next = slow.Next.Next
return dummy.Next // 不能返回head,案例4就是删掉头结点,哨兵很好的处理了这种情况
}203. 移除链表元素
描述
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:

输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]示例 2:
输入:head = [], val = 1
输出:[]示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]核心思想
可能删去head,所以要空头结点dummy
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func removeElements(head *ListNode, val int) *ListNode {
dummy := &ListNode{Next: head}
cur := head
pre := dummy
for cur != nil {
if cur.Val == val {
pre.Next = cur.Next
cur = pre.Next
}else{
pre = cur
cur = cur.Next
}
}
return dummy.Next
}3217. 从链表中移除在数组中存在的节点
描述
给你一个整数数组 nums 和一个链表的头节点 head。从链表中移除所有存在于 nums 中的节点后,返回修改后的链表的头节点。
示例 1:
输入: nums = [1,2,3], head = [1,2,3,4,5]
输出: [4,5]
解释:

移除数值为 1, 2 和 3 的节点。
示例 2:
输入: nums = [1], head = [1,2,1,2,1,2]
输出: [2,2,2]
解释:

移除数值为 1 的节点。
示例 3:
输入: nums = [5], head = [1,2,3,4]
输出: [1,2,3,4]
解释:

链表中不存在值为 5 的节点。
核心思想
用map进行数组存在元素的O1查找
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func modifiedList(nums []int, head *ListNode) *ListNode {
// 用map代替遍历数组
m := make(map[int]bool)
for _,x := range nums {
m[x] = true
}
dummy := &ListNode{Next: head}
pre := dummy
cur := head
for cur != nil {
if m[cur.Val] {
pre.Next = cur.Next
cur = pre.Next
} else{
pre = cur
cur = cur.Next
}
}
return dummy.Next
}83. 删除排序链表中的重复元素
描述
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:

输入:head = [1,1,2]
输出:[1,2]示例 2:

输入:head = [1,1,2,3,3]
输出:[1,2,3]核心思想
要注意已经有序,不需要用map查找,判断前后一致即可
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func deleteDuplicates(head *ListNode) *ListNode {
// m := make(map[int]bool)
// 已经有序,无需map
if head == nil {
return head
}
dummy := &ListNode{Next: head}
pre := head
cur := head.Next
for cur != nil {
if pre.Val == cur.Val {
// 已存在
pre.Next = cur.Next
cur = pre.Next
}else{
pre = pre.Next
cur = cur.Next
}
}
return dummy.Next
}92. 反转链表 II
描述
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。
示例 1:

输入:head = [1,2,3,4,5], left = 2, right = 4
输出:[1,4,3,2,5]示例 2:
输入:head = [5], left = 1, right = 1
输出:[5]核心思想

代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func reverseBetween(head *ListNode, left int, right int) *ListNode {
// 移植206反转链表代码,把left作为head,right-left作为for的次数
if head == nil || head.Next == nil {
return head
}
dummy := &ListNode{0, head}
cur := head
pre := dummy
n := right - left
for left > 1 {
pre = pre.Next
cur = cur.Next
left--
}
p0 := pre
for n >= 0 {
next := cur.Next
cur.Next = pre
pre = cur
cur = next
n--
}
// p0.Next 还是2,2的next是谁不重要,现在要把2的next改成5
p0.Next.Next = cur
p0.Next = pre
return dummy.Next
}876. 链表的中间结点
描述
给你单链表的头结点 head ,请你找出并返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
示例 1:

输入:head = [1,2,3,4,5]
输出:[3,4,5]
解释:链表只有一个中间结点,值为 3 。示例 2:

输入:head = [1,2,3,4,5,6]
输出:[4,5,6]
解释:该链表有两个中间结点,值分别为 3 和 4 ,返回第二个结点。核心思想
本题是234的先导题,用以返回中心点
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func middleNode(head *ListNode) *ListNode {
slow := head
fast := head
for fast.Next != nil {
slow = slow.Next
if fast.Next.Next == nil {
break
}
fast = fast.Next.Next
}
return slow
}2095. 删除链表的中间节点
描述
给你一个链表的头节点 head 。删除 链表的 中间节点 ,并返回修改后的链表的头节点 head 。
长度为 n 链表的中间节点是从头数起第 ⌊n / 2⌋ 个节点(下标从 0 开始),其中 ⌊x⌋ 表示小于或等于 x 的最大整数。
- 对于
n=1、2、3、4和5的情况,中间节点的下标分别是0、1、1、2和2。
示例 1:

输入:head = [1,3,4,7,1,2,6]
输出:[1,3,4,1,2,6]
解释:
上图表示给出的链表。节点的下标分别标注在每个节点的下方。
由于 n = 7 ,值为 7 的节点 3 是中间节点,用红色标注。
返回结果为移除节点后的新链表。 示例 2:

输入:head = [1,2,3,4]
输出:[1,2,4]
解释:
上图表示给出的链表。
对于 n = 4 ,值为 3 的节点 2 是中间节点,用红色标注。示例 3:

输入:head = [2,1]
输出:[2]
解释:
上图表示给出的链表。
对于 n = 2 ,值为 1 的节点 1 是中间节点,用红色标注。
值为 2 的节点 0 是移除节点 1 后剩下的唯一一个节点。核心思想
876基础上修改,找中心点前面一个节点
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func deleteMiddle(head *ListNode) *ListNode {
dummy := &ListNode{0, head}
slow := dummy
fast := head
for fast.Next != nil {
slow = slow.Next
if fast.Next.Next == nil {
break
}
fast = fast.Next.Next
}
// slow 停在中心点前一个
slow.Next = slow.Next.Next
return dummy.Next
}2130. 链表最大孪生和
描述
在一个大小为 n 且 n 为 偶数 的链表中,对于 0 <= i <= (n / 2) - 1 的 i ,第 i 个节点(下标从 0 开始)的孪生节点为第 (n-1-i) 个节点 。
- 比方说,
n = 4那么节点0是节点3的孪生节点,节点1是节点2的孪生节点。这是长度为n = 4的链表中所有的孪生节点。
孪生和 定义为一个节点和它孪生节点两者值之和。
给你一个长度为偶数的链表的头节点 head ,请你返回链表的 最大孪生和 。
示例 1:

输入:head = [5,4,2,1]
输出:6
解释:
节点 0 和节点 1 分别是节点 3 和 2 的孪生节点。孪生和都为 6 。
链表中没有其他孪生节点。
所以,链表的最大孪生和是 6 。示例 2:

输入:head = [4,2,2,3]
输出:7
解释:
链表中的孪生节点为:
- 节点 0 是节点 3 的孪生节点,孪生和为 4 + 3 = 7 。
- 节点 1 是节点 2 的孪生节点,孪生和为 2 + 2 = 4 。
所以,最大孪生和为 max(7, 4) = 7 。核心思想
On空间,链表转数组
O1空间,找中心点,反转后半部分再双指针遍历
代码
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func pairSum(head *ListNode) int {
// On空间,链表转数组
// O1空间,找中心点,反转后半部分再双指针遍历
if head.Next.Next == nil {
return head.Val + head.Next.Val
}
dummy := &ListNode{0, head}
slow := dummy
fast := head
for fast.Next != nil {
slow = slow.Next
if fast.Next.Next == nil {
break
}
fast = fast.Next.Next
}
// pre := slow
var pre *ListNode
cur := slow.Next
for cur != nil {
next := cur.Next
cur.Next = pre
pre = cur
cur = next
}
ans := 0
p1 := head
p2 := pre
for p2 != nil { // p2链的尾部是我们人为创建的空结点pre
count := p1.Val + p2.Val
if count > ans {
ans = count
}
p1 = p1.Next
p2 = p2.Next
}
return ans
}1475. 商品折扣后的最终价格
描述
给你一个数组 prices ,其中 prices[i] 是商店里第 i 件商品的价格。
商店里正在进行促销活动,如果你要买第 i 件商品,那么你可以得到与 prices[j] 相等的折扣,其中 j 是满足 j > i 且 prices[j] <= prices[i] 的 最小下标 ,如果没有满足条件的 j ,你将没有任何折扣。
请你返回一个数组,数组中第 i 个元素是折扣后你购买商品 i 最终需要支付的价格。
示例 1:
输入:prices = [8,4,6,2,3]
输出:[4,2,4,2,3]
解释:
商品 0 的价格为 price[0]=8 ,你将得到 prices[1]=4 的折扣,所以最终价格为 8 - 4 = 4 。
商品 1 的价格为 price[1]=4 ,你将得到 prices[3]=2 的折扣,所以最终价格为 4 - 2 = 2 。
商品 2 的价格为 price[2]=6 ,你将得到 prices[3]=2 的折扣,所以最终价格为 6 - 2 = 4 。
商品 3 和 4 都没有折扣。示例 2:
输入:prices = [1,2,3,4,5]
输出:[1,2,3,4,5]
解释:在这个例子中,所有商品都没有折扣。示例 3:
输入:prices = [10,1,1,6]
输出:[9,0,1,6]核心思想
单调栈思想
代码
func finalPrices(prices []int) []int {
// 找到右边第一个比i小的,就是折扣
// 从右往左,遇到栈顶比自己大的,出栈,让小的坐栈顶
// 如果栈顶比自己小,记下答案
n := len(prices)
st := []int{}
ans := make([]int, n)
for i := n-1; i>=0; i-- {
cur := prices[i]
for len(st) > 0 && st[len(st)-1] > cur {
// 持续出栈直到栈为空或者栈顶元素小于等于 cur
st = st[:len(st)-1]
}
if len(st) > 0 {
ans[i] = cur - st[len(st)-1]
}else{
ans[i] = cur
}
st = append(st, cur)
}
return ans
}496. 下一个更大元素 I
描述
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
- 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
- 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4].
输出:[3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。
- 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。核心思想
单调栈
代码
func nextGreaterElement(nums1 []int, nums2 []int) []int {
// 单调栈,从大到小,底部存最大
// 从右往左,当前i,如果栈顶比i大,那这个数就是ans[i];
// 如果栈顶比i小,那就一直出栈,i当栈顶
n := len(nums2)
st := []int{}
m := make(map[int]int)
for i := n - 1; i >= 0; i-- {
cur := nums2[i]
for len(st) > 0 && cur >= st[len(st)-1] {
st = st[:len(st)-1]
}
if len(st) > 0 {
m[cur] = st[len(st)-1] // 栈顶
}else{
m[cur] = -1
}
st = append(st, cur)
}
for i := range nums1 {
nums1[i] = m[nums1[i]]
}
return nums1
}503. 下一个更大元素 II
描述
给定一个循环数组 nums ( nums[nums.length - 1] 的下一个元素是 nums[0] ),返回 nums 中每个元素的 下一个更大元素 。
数字 x 的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1 。
示例 1:
输入: nums = [1,2,1]
输出: [2,-1,2]
解释: 第一个 1 的下一个更大的数是 2;
数字 2 找不到下一个更大的数;
第二个 1 的下一个最大的数需要循环搜索,结果也是 2。示例 2:
输入: nums = [1,2,3,4,3]
输出: [2,3,4,-1,4]核心思想
找到最大的数,看成数组末尾,还是单调栈做法
代码
func nextGreaterElements(nums []int) []int {
// 首先遍历一遍,找到最大的数,把他当做数组尾部,当成496做
n := len(nums)
maxIndex := 0
for i := range nums {
if nums[i] > nums[maxIndex] {
maxIndex = i
}
}
st := []int{}
i := maxIndex
for count := 1; count <= n; count++ {
curIndex := (i + n ) % n // 注意i会变成负数
cur := nums[curIndex]
for len(st) > 0 && cur >= st[len(st)-1] {
st = st[:len(st)-1]
}
if len(st) > 0 {
nums[curIndex] = st[len(st)-1]
}else{
nums[curIndex] = -1
}
st = append(st, cur)
i--
}
return nums
}2815. 数组中的最大数对和
描述
给你一个下标从 0 开始的整数数组 nums 。请你从 nums 中找出和 最大 的一对数,且这两个数数位上最大的数字相等。
返回最大和,如果不存在满足题意的数字对,返回 -1 。
示例 1:
输入:nums = [51,71,17,24,42]
输出:88
解释:
i = 1 和 j = 2 ,nums[i] 和 nums[j] 数位上最大的数字相等,且这一对的总和 71 + 17 = 88 。
i = 3 和 j = 4 ,nums[i] 和 nums[j] 数位上最大的数字相等,且这一对的总和 24 + 42 = 66 。
可以证明不存在其他数对满足数位上最大的数字相等,所以答案是 88 。示例 2:
输入:nums = [1,2,3,4]
输出:-1
解释:不存在数对满足数位上最大的数字相等。核心思想
用0-9数组numArr,去存数位最大为i的数x,numArr[i] = x, x数位最大是i。结果ans维护数位相同的最大和。
遍历nums,如果目的numArr为空,放入;如果目的numArr不为空,求和,和结果ans比较大小,大就更新ans;如果非空且比目的数大,更新numArr,以便下一次求和。
代码
func maxSum(nums []int) int {
var numArr [10]int
for i := range numArr {
numArr[i] = math.MinInt // 初始化最小值,有大的便可取代
}
ans := -1
for _, x := range nums {
index := findBiggestNum(x)
if numArr[index] > 0 {
ans = max(ans, x+numArr[index])
if x > numArr[index] {
numArr[index] = x // 比0-9数组还大,也放进去
}
}else{
// 0-9数组 的index位置还没有数,存入
numArr[index] = x
}
}
return ans
}
func findBiggestNum(x int) int {
res := 0
for x != 0 {
if x % 10 > res {
res = x % 10
}
x = x / 10
}
return res
}也可以用map
func maxSum(nums []int) int {
maxMap := make(map[int]int)
ans := -1
for _, x := range nums {
key := findBiggestNum(x)
if value,exists := maxMap[key];exists {
ans = max(ans, x+value)
if x > value {
maxMap[key] = x
}
}else{
// 0-9数组 的index位置还没有数,存入
maxMap[key] = x
}
}
return ans
}
func findBiggestNum(x int) int {
res := 0
for x != 0 {
if x % 10 > res {
res = x % 10
}
x = x / 10
}
return res
}844. 比较含退格的字符串
描述
给定 s 和 t 两个字符串,当它们分别被输入到空白的文本编辑器后,如果两者相等,返回 true 。# 代表退格字符。
注意:如果对空文本输入退格字符,文本继续为空。
示例 1:
输入:s = "ab#c", t = "ad#c"
输出:true
解释:s 和 t 都会变成 "ac"。示例 2:
输入:s = "ab##", t = "c#d#"
输出:true
解释:s 和 t 都会变成 ""。示例 3:
输入:s = "a#c", t = "b"
输出:false
解释:s 会变成 "c",但 t 仍然是 "b"。核心思想
栈
代码
func backspaceCompare(s string, t string) bool {
if returnStr(s) == returnStr(t) {
return true
}
return false
}
func returnStr(s string) (ans string) {
stack := []byte{}
for i := 0; i < len(s); i++ {
if len(stack) > 0 && s[i] == '#' {
// 退栈
stack = stack[:len(stack)-1]
}else if s[i] != '#' {
// 压栈
stack = append(stack, s[i])
}
}
ans = string(stack)
return
}101. 对称二叉树
描述
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:

输入:root = [1,2,2,3,4,4,3]
输出:true示例 2:

输入:root = [1,2,2,null,3,null,3]
输出:false核心思想
递归,
代码
/**
* Definition for a binary tree node.
* type TreeNode struct {
* Val int
* Left *TreeNode
* Right *TreeNode
* }
*/
func isSymmetric(root *TreeNode) bool {
var dfs func(r1 *TreeNode, r2 *TreeNode) bool
dfs = func(r1 *TreeNode, r2 *TreeNode) bool {
if r1 == nil || r2 == nil{
return r1 == r2
}
return r1.Val == r2.Val && dfs(r1.Left, r2.Right) && dfs(r1.Right, r2.Left)
}
return dfs(root.Left, root.Right)
}